
基础概念
消息队列-RabbitMQ篇章- 专栏 -KuangStudy
技术对比:
比较常见的MQ实现:
ActiveMQ
RabbitMQ
RocketMQ
Kafka
几种常见MQ的对比:
RabbitMQ | ActiveMQ | RocketMQ | Kafka | |
|---|---|---|---|---|
公司/社区 | Rabbit | Apache | 阿里 | Apache |
开发语言 | Erlang | Java | Java | Scala&Java |
协议支持 | AMQP,XMPP,SMTP,STOMP | OpenWire,STOMP,REST,XMPP,AMQP | 自定义协议 | 自定义协议 |
可用性 | 高 | 一般 | 高 | 高 |
单机吞吐量 | 一般 | 差 | 高 | 非常高 |
消息延迟 | 微秒级 | 毫秒级 | 毫秒级 | 毫秒以内 |
消息可靠性 | 高 | 一般 | 高 | 一般 |
追求可用性:Kafka、 RocketMQ 、RabbitMQ
追求可靠性:RabbitMQ、RocketMQ
追求吞吐能力:RocketMQ、Kafka
追求消息低延迟:RabbitMQ、Kafka
消息中间件核心
1:消息的协议
2:消息的持久化机制
3:消息的分发策略
4:消息的高可用,高可靠
5:消息的容错机制
安装
单机安装
官网:rabbitmq.com
权限账户
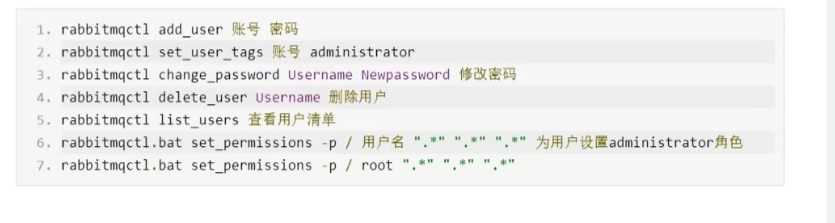 集群安装
集群安装
配置文件
version: "3"
networks:
common:
external:
name: mynet
rabbitymq_cluster:
external:
name: rabbitymq-cluster
# 启动3个rabbitmq容器节点
# rabbitmq1为disk主节点
# rabbitmq2、rabbitmq3为ram从节点
services:
rabbitmq-master:
image: rabbitmq:management
deploy:
resources:
limits:
cpus: '2'
memory: 8G
restart_policy:
condition: on-failure
environment:
- RABBITMQ_DEFAULT_USER=user
- RABBITMQ_DEFAULT_PASS=xxxxx
- RABBITMQ_ERLANG_COOKIE=rabbitmq_erlang_cookie
restart: always
hostname: rabbitmq-master
container_name: rabbitmq-master
networks:
rabbitymq_cluster:
ipv4_address: 192.168.1.2
common:
ipv4_address: 192.168.0.4
volumes:
- ./rabbitmq-master:/var/lib/rabbitmq
- /etc/localtime:/etc/localtime
ports:
- 6001:5672
- 6002:1883
- 6003:15672
rabbitmq-cluster-1:
image: rabbitmq:management
deploy:
resources:
limits:
cpus: '2'
memory: 8G
restart_policy:
condition: on-failure
environment:
- RABBITMQ_DEFAULT_USER=user
- RABBITMQ_DEFAULT_PASS=xxxxx
- RABBITMQ_ERLANG_COOKIE=rabbitmq_erlang_cookie
restart: always
hostname: rabbitmq-cluster-1
container_name: rabbitmq-cluster-1
networks:
rabbitymq_cluster:
ipv4_address: 192.168.1.3
# mynet:
# ipv4_address: 192.168.0.4
volumes:
- ./rabbitmqCluster-1:/var/lib/rabbitmq
- /etc/localtime:/etc/localtime
ports:
- 6011:5672
rabbitmq-cluster-2:
image: rabbitmq:management
deploy:
resources:
limits:
cpus: '2'
memory: 8G
restart_policy:
condition: on-failure
environment:
- RABBITMQ_DEFAULT_USER=user
- RABBITMQ_DEFAULT_PASS=xxxxx
- RABBITMQ_ERLANG_COOKIE=rabbitmq_erlang_cookie
restart: always
hostname: rabbitmq-cluster-2
container_name: rabbitmq-cluster-2
networks:
rabbitymq_cluster:
ipv4_address: 192.168.1.4
# mynet:
# ipv4_address: 192.168.0.4
volumes:
- ./rabbitmqCluster-2:/var/lib/rabbitmq
- /etc/localtime:/etc/localtime
ports:
- 6021:5672初始化脚本
#!/bin/bash
#reset first node
echo "Reset first rabbitmq node."
docker exec rabbitmq-master /bin/bash -c 'rabbitmqctl stop_app'
docker exec rabbitmq-master /bin/bash -c 'rabbitmqctl reset'
docker exec rabbitmq-master /bin/bash -c 'rabbitmqctl start_app'
#build cluster
echo "Starting to build rabbitmq cluster with two ram nodes."
docker exec rabbitmq-cluster-1 /bin/bash -c 'rabbitmqctl stop_app'
docker exec rabbitmq-cluster-1 /bin/bash -c 'rabbitmqctl reset'
docker exec rabbitmq-cluster-1 /bin/bash -c 'rabbitmqctl join_cluster --ram rabbit@rabbitmq-master'
docker exec rabbitmq-cluster-1 /bin/bash -c 'rabbitmqctl start_app'
docker exec rabbitmq-cluster-2 /bin/bash -c 'rabbitmqctl stop_app'
docker exec rabbitmq-cluster-2 /bin/bash -c 'rabbitmqctl reset'
docker exec rabbitmq-cluster-2 /bin/bash -c 'rabbitmqctl join_cluster --ram rabbit@rabbitmq-master'
docker exec rabbitmq-cluster-2 /bin/bash -c 'rabbitmqctl start_app'
#check cluster status
echo "Check cluster status:"
docker exec rabbitmq-master /bin/bash -c 'rabbitmqctl cluster_status'
docker exec rabbitmq-cluster-1 /bin/bash -c 'rabbitmqctl cluster_status'
docker exec rabbitmq-cluster-2 /bin/bash -c 'rabbitmqctl cluster_status'
#echo "Starting to create user."
#docker exec rabbitmq-master /bin/bash -c 'rabbitmqctl add_user rabbitmq @rabbitmq0012'
#echo "Set tags for new user."
#docker exec rabbitmq-master /bin/bash -c 'rabbitmqctl set_user_tags rabbitmq administrator'
#echo "Grant permissions to new user."
#docker exec rabbitmq-master /bin/bash -c "rabbitmqctl set_permissions -p '/' rabbitmq '.*' '.*' '.*'"web端开启镜像集群配置
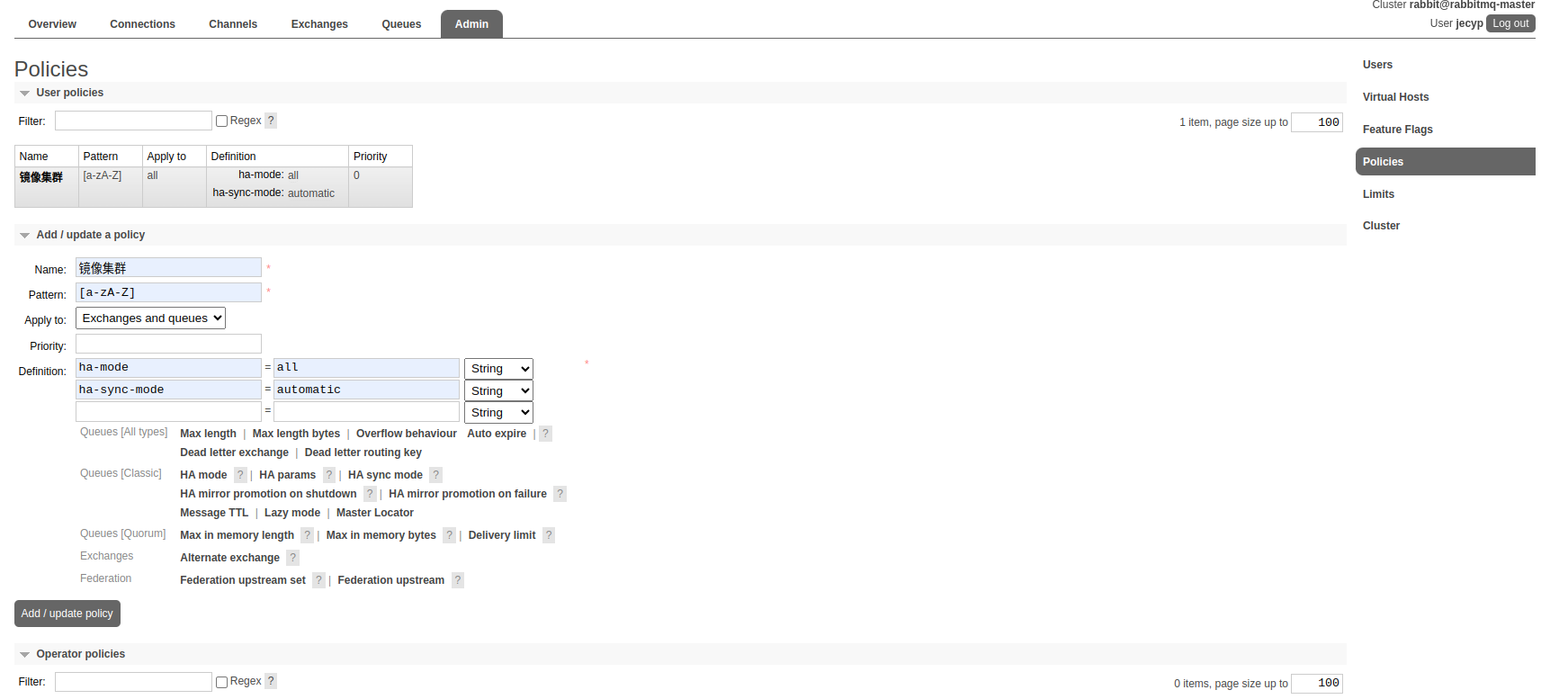
消息的协议
amqp协议-》tcp/ip协议
语法:用户数据与控制信息的结构和格式,以及数据的顺序
语义:控制信息每个部分的意义。
时序:事件发生顺序
不使用http协议
1:http请求报文头和响应头比较复杂,包含cookie,数据的加密解密,状态码等等
2:http大部分都是短链接。中间件一般需要长期的获取信息,保证消息和数据的高可靠和稳健
常见的协议:AMQP,MQTT,Kafka,OpenMessage协议
AMQP
Erlangshi开发的RabbitMq
特性:
1、分布式事务支持
2、持久性
3、高性能和高可靠的消息处理
MQTT
是一个即时通讯协议,常用于物联网架构
特性
1、轻量
2、结构简单
3、传输快,不支持事务
应用场景
1、技术能力有限
2、低带宽
2、网络不稳定
OpenMessage协议
rocketMq专用
特点:
结构简单,解析速度快,支持事务和持久化设计
Kafka协议
基于tco/ip的二进制协议.消息内部通过长度来分割,由一些基本数据类型组成
特性:
结构简单,解析速度快,无事务支持,持久化
持久化
文件存储 | 数据库 | |
|---|---|---|
ActiveMq | 支持 | 支持 |
RabbitMq | 支持 | |
Kafka | 支持 | |
RocketMq | 支持 |
分发策略
角色
1:生产者
2:存储消息
3:消费者
mq一般为push(推)的机制
ActiveMq | RabbitMq | Kafka | RocketMq | |
|---|---|---|---|---|
发布订阅 | 支持 | 支持 | 支持 | 支持 |
轮询分发 | 支持 | 支持 | 支持 | |
公平分发 | 支持 | 支持 | ||
重发 | 支持 | 支持 | 支持 | |
消息拉取 | 支持 | 支持 | 支持 |
发布订阅
一条消息会被所有订阅的服务消息
轮询发布
不论服务器的性能如何,都是公平的.一条消息只能被消费一次
公平分发
按照性能来公平分发,一条消息只能被消费一次
重发
失败重发
消息拉取
被动拉取,rpc
消息队列的高可用和高可靠
高可用
不容易崩,例如集群
集群模式模式-master-slave主从共享数据
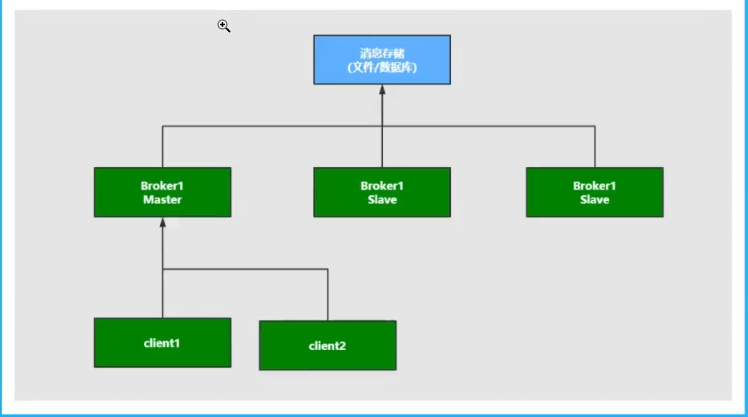
生产者将消费者发送到master节点,所有连接的消息队列共享这个数据区域,master节点负责写入,一旦master挂断,slave节点继续提供服务
master-slave主从同步
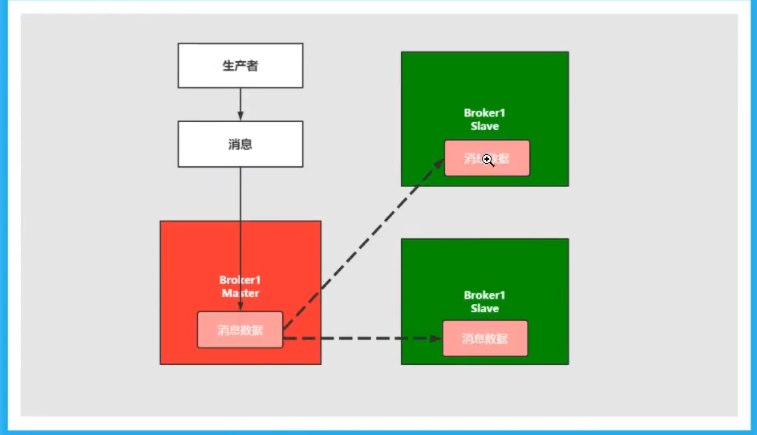
写入消息在master主节点上,但是主节点会同步数据到slave节点形成副本,和zookeeper或者redis主从机制类似.
多主集群同步部署
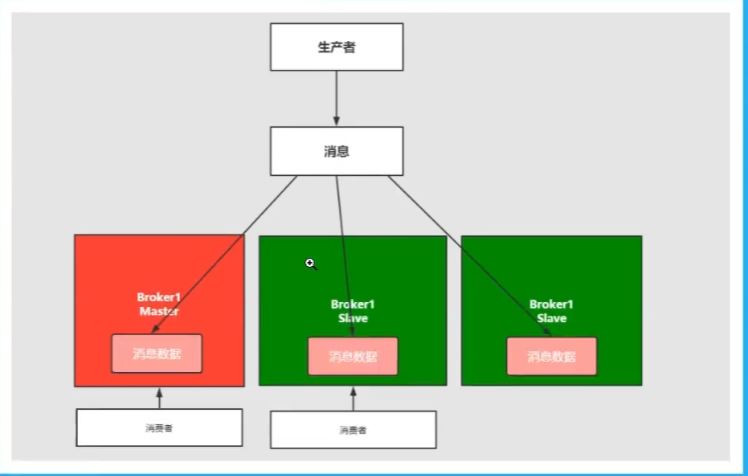
和第二种区别不大,区别为写入可以往任意节点去写入,每个主都写入一份数据,多写多读
多主集群转发部署模式
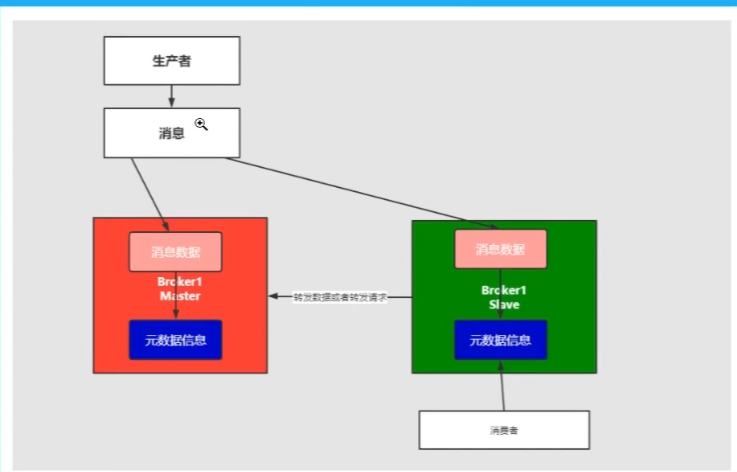
如果插入的数据是broker-1种,元数据信息会存储数据的相关信息和记录存放的位置
会对描述信息也就是元数据进行同步,如果消费者在broker-2中进行消费,发现没有,则从对应的元数据中查询,然后返回对应消息信息
master-slave与Breoker-cluster组合的方案
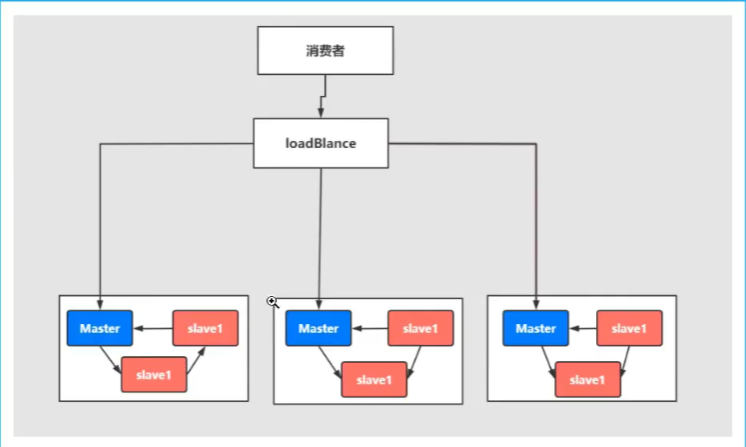
时序多主多从的热备机制来完成消息的高可用以及数据的热备机制,在生产规模达到一定规模用的多
总结
1:消息共享
2:元数据共享
3:消息同步
高可靠
系统可以无故障地持续运行。例如异常、报错导致无法运行,例如持久化
1:消息的传输:通过协议来保证系统间数据解析的正常性
2:消息的存储可靠:通过持久化来保证消息的可靠性
rabbitmq角色分类
none
不能访问web页面
management:查看自己相关节点信息
列出自己可以通过amqp登入的虚拟机
查看自己的虚拟机节点 virtual hosts的quueues,exchanges和bindings信息
查看和关闭自己的channels和connections
查看有关自己的虚拟机节点virtual hosts的统计信息。包括其他用户在这个节点virtual hosts中的信息
Policymaker
包含management所有权限
查看,创建和删除自己的virtual hosts所属的policies和parameters信息
Monitoring
包含management所有权限
罗列出所有virtual hosts,包括不登录的virtual hosts
查看其他用户的connections和channels信息
查看节点级别的数据,如clustering和memory使用信息
查看所有的virtual hosts的全局统计信息
Administrator
最高权限
可以创建和删除virtual hosts
可以查看,创建和删除users
查看创建permissions
关闭所有用的connections
AMQP流程
生产者流程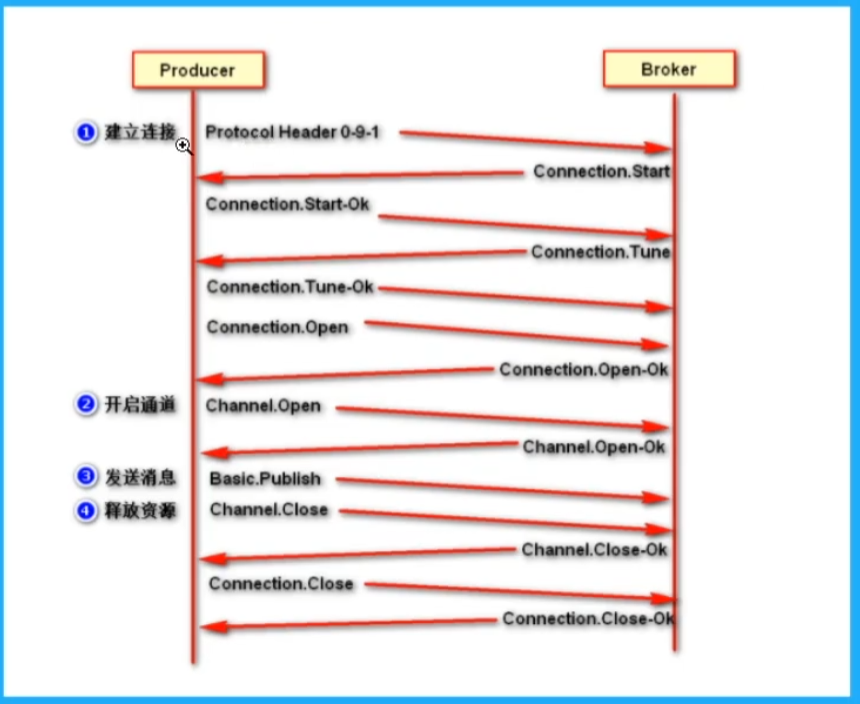
消费者流程
架构
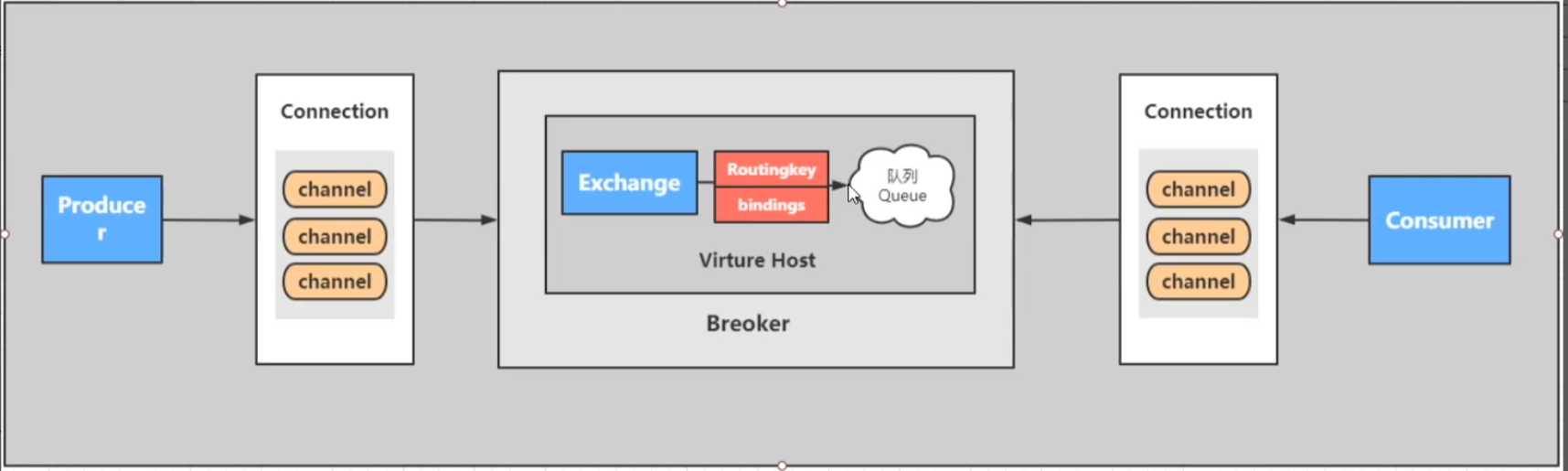

支持消息的模式
[官方文档] https://www.rabbitmq.com/getstarted.html
核心是消息发送到交换机。交换机根据模式和规则发送到队列,消费者消费队列
简单模式
交换机类型为direct
消息生产者发给交换机,交换机发给队列,消费者消费消息
生产者:多个生产者可以往一个队列发送消息(队列不为独占时)
消费者:可以多个消费者同时消费一个队列,轮询发布。按照消费者注册顺序分发,一条消息只会分发一次
发布订阅模式fanout
交换机类型为fanout
和redis发布订阅相同。给所有订阅的
需要创建一个fanout类型的交换机-xx。生产者往该交换机xx发消息,队列绑定该交换机xx,同一条消息所有绑定xx交换机的队列都收到该条消息。消费者消费队列
路由模式routing
交换机类型为direct
需要创建一个direct类型的交换机-xx。生产者给交换机xx发消息时,额外携带一个routing key。队列在绑定交换机xx时,指定接收routing key。该消息只会发给routingkey匹配的队列。
两个队列指定相同routing key到一个交换机时,都会收到相同的消息
当该交换机发送一条没有指定routing key的消息时,如果有同样没有指定routing key的队列,则发送到该队列,否则发送失败。如果有多个则都会收到消息
主题模式 topic
交换机类型为topic
在routing的基础上对key采用模糊匹配的形式。有两种通配符*和#
*:有且只能有一级#:可有可无,0级,1级,n级都可以
例如:
com.# | .cource. | #.order.* | ..studest | |
|---|---|---|---|---|
com | y | n | n | n |
com.cource.order | y | y | n | n |
com.order.cource | y | n | y | n |
com.cource | y | n | n | n |
com.order | y | n | n | n |
com.order.studest | y | y | n | y |
参数模式 header
交换机类型为header
通过key-value的形式进行匹配.必须key对应的value值相匹配
当header指定多个时,必须全部匹配
工作模式 work
前面的几种模式主要顶对,生产者的消息通过交换机分发给那些队列
工作模式的定义是
当有多个消费者时,我们的消息会被哪个消费者消费呢,我们又该如何均衡消费者消费信息的多少呢?
主要有两种模式:
1、轮询模式的分发:一个消费者一条,按均分配;
2、公平分发:根据消费者的消费能力进行公平分发,处理快的处理的多,处理慢的处理的少;按劳分配;
轮询分发:默认为该模式,应答方式为自动应答
公平分发:指定qos(一次性从队列获取多少条数据)和应答方式为手动应答,开启公平分发
springboot整合
spring-amqp定义了一系列发送消息的规范以及接口。
其中rabbitmq是其实现
gitea代码
有两种方式,
一种为通过配置文件声明bean的形式完成,交换机、队列的声明,以及交换机和队列的绑定。
另一种为通过注解@RabbitListener完成声明以及绑定
生产者通过RabbitTemplate类发送消息
消费者通过@RabbitListener(queues = "email.direct.queue")和@RabbitHandler完成消费
boot配置详细信息:消息队列-RabbitMQ篇章- 专栏 -KuangStudy
消息转换
Spring会把你发送的消息序列化为字节发送给MQ,接收消息的时候,还会把字节反序列化为Java对象。
只不过,默认情况下Spring采用的序列化方式是JDK序列化。众所周知,JDK序列化存在下列问题:
数据体积过大
有安全漏洞
可读性差
DK序列化方式并不合适。我们希望消息体的体积更小、可读性更高,因此可以使用JSON方式来做序列化和反序列化。
在publisher和consumer两个服务中都引入依赖:
<dependency>
<groupId>com.fasterxml.jackson.dataformat</groupId>
<artifactId>jackson-dataformat-xml</artifactId>
<version>2.9.10</version>
</dependency>配置消息转换器。
在启动类中添加一个Bean即可:
@Bean
public MessageConverter jsonMessageConverter(){
return new Jackson2JsonMessageConverter();
}高级特性
过期时间ttl
过期时间TTL表示可以对消息设置预期的时间,在这个时间内都可以被消费者接收获取;过了之后消息将自动被删除。RabbitMQ可以对消息和队列设置TTL。目前有两种方法可以设置。
第一种方法是通过队列属性设置,队列中所有消息都有相同的过期时间。
第二种方法是对消息进行单独设置,每条消息TTL可以不同。
如果上述两种方法同时使用,则消息的过期时间以两者之间TTL较小的那个数值为准。消息在队列的生存时间一旦超过设置的TTL值,就称为dead message被投递到死信队列, 消费者将无法再收到该消息。
队列设置TTL
设置args参数x-message-ttl
@Bean("ttlFanoutQueue")
public Queue ttlFanoutQueue(){
// durable :是否持久化,默认false。持久化代表队列会被存储到磁盘上,当重启时依然存在,
// exclusive:默认false 只有被当前创建的链接使用,而且当连接关闭后队列即刻删除,优先级高于durable
// autoDelete:是否自动删除,当没有生产者或者消费者使用此队列,该队列自动删除
HashMap<String, Object> args = new HashMap<>();
args.put("x-message-ttl", 5000);
return new Queue("fanout.ttl.queue",true,false,false, args);
}消息设置TTL
单独设置消息过期时间.过期消息是直接移除,而不是进入死信队列
public void makeOrderByDirectAndTtlMessage(String userId, String productId, int num){
String orderId = UUID.randomUUID().toString();
System.out.println("direct ttl用户:"+userId+",订单编号:"+orderId);
rabbitTemplate.convertAndSend(RabbitmqConfig.DIRECT_ORDER_EXCHANGE, "ttl-message", orderId, message -> {
// 消息设置过期时间
message.getMessageProperties().setExpiration("10000");
message.getMessageProperties().setContentEncoding("UTF-8");
return message;
});
}死信队列
DLX,全称为Dead-Letter-Exchange , 可以称之为死信交换机,也有人称之为死信邮箱。当消息在一个队列中变成死信(dead message)之后,它能被重新发送到另一个交换机中,这个交换机就是DLX ,绑定DLX的队列就称之为死信队列。
消息变成死信,可能是由于以下的原因:
消息被拒绝
消息过期
队列达到最大长度
DLX也是一个正常的交换机,和一般的交换机没有区别,它能在任何的队列上被指定,实际上就是设置某一个队列的属性。当这个队列中存在死信时,Rabbitmq就会自动地将这个消息重新发布到设置的DLX上去,进而被路由到另一个队列,即死信队列。
要想使用死信队列,只需要在定义队列的时候设置队列参数 x-dead-letter-exchange 指定交换机即可。

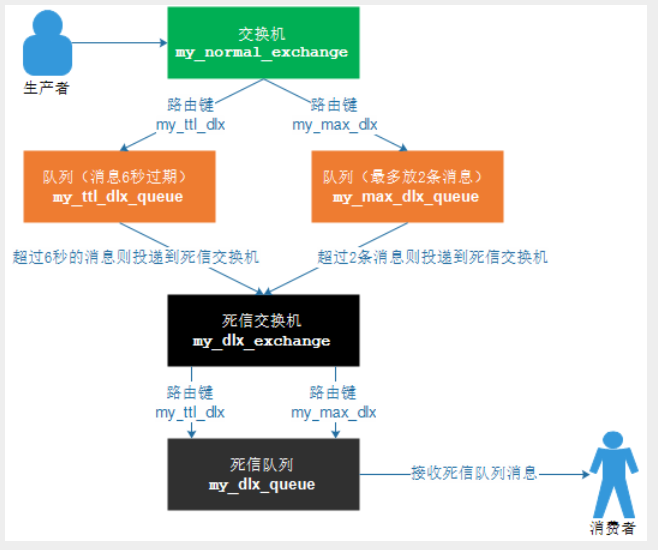 需要注意::如果一个队列已经创建,如果修改配置不会生效。 代码启动是会报错。只能通过删除重新创建才会生效。但是线上最好创建一个新的队列来替换旧队列,而不是删除
需要注意::如果一个队列已经创建,如果修改配置不会生效。 代码启动是会报错。只能通过删除重新创建才会生效。但是线上最好创建一个新的队列来替换旧队列,而不是删除
// 声明死信交换机为dead类型
@Bean("deadDirectExchange")
public DirectExchange deadDirect(){
return new DirectExchange("dead_direct_exchange",true,false);
}
// 声明死信队列
@Bean("deadDirectQueue")
public Queue deadDirectQueue(){
return new Queue("direct.dead.queue",true,false,false);
}
@Bean
public Binding deadDirectQueueBind(@Qualifier("deadDirectQueue") Queue deadDirectQueue,
@Qualifier("deadDirectExchange") DirectExchange directExchange){
return BindingBuilder
.bind(deadDirectQueue)
.to(directExchange)
.with("dead");
}
@Bean("ttlFanoutQueue")
public Queue ttlFanoutQueue(){
// 定义配置参数,x-message-ttl 过期时间, x-max-length队列最大长度
// 但触发过期时间,或者最大长度时, 配置转发的死信队列.需要配置对应的交换机 x-dead-letter-exchange
// 如果交换机类型需要配置路由 x-dead-letter-routing-key
HashMap<String, Object> args = new HashMap<>();
args.put("x-message-ttl", 5000);
args.put("x-max-length", 5);
args.put("x-dead-letter-exchange", "deadDirectExchange");
args.put("x-dead-letter-routing-key", "dead");
return new Queue("fanout.ttl.queue",true,false,false, args);
}分布式事务
生产者
生产者发送消息,并开启消息确定。用以确定消息成功发送到mq。数据可以记录状态,如果失败,通过例如定时器,进行重试。配置文件,配置消息开启手动应答ack
spring:
rabbitmq:
username: user
password: 'xxxx'
virtual-host: /
# host: 192.168.201.102
# port: 5672
#这个配置是保证提供者确保消息推送到交换机中,不管成不成功,都会回调
publisher-confirm-type: correlated
#保证交换机能把消息推送到队列中
publisher-returns: true
#这个配置是保证消费者会消费消息,手动确认
listener:
simple:
acknowledge-mode: manual
#以下是rabbitmqTemplate配置
template:
mandatory: true
addresses: 192.168.201.102:5672
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.201.102:3306/mq-order?allowMultiQueries=true&useUnicode=true&characterEncoding=UTF-8&useSSL=false&serverTimezone=GMT%2B8
username: user
password: xxxx消费者
消费者订阅消息。如果失败,一般重试的方式有:
控制重发的次数 + 死信
控制重试次数可通过配置文件定义. 重试达到一定次数,如果配置了死信队列,发送给死信队列
spring:
rabbitmq:
addresses: 192.168.201.102:5672
username: user
password: xxxx
virtual-host: /
#开始收到ack,让程序去控制mq的消息重发、删除和转移
listener:
simple:
acknowledge-mode: manual
retry:
enabled: true #开启重试
max-attempts: 3 # 最大重试次数
initial-interval: 2000ms # 重试间隔时间try+catch+ack
开启手动应答机制,try/catch错误,如果错误则拒绝该消息. 拒绝不会触发重试
@RabbitListener(queues = "order.fanout.queue")
@RabbitHandler
public void save(Map<String, Object> msg , Channel channel, Message message) throws IOException {
System.out.println("收到消息msg:"+msg);
System.out.println("收到message:"+message.toString());
System.out.println("收到channel:"+channel.toString());
int update;
try {
String sqlString = "insert into distribution(orderId, uesrId, xiaogeId, content, createTime) VALUES (?,?,?,?,?);";
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
// ObjectMapper objectMapper = new ObjectMapper();
// msg = new String(Base64.getDecoder().decode(msg.getBytes()));
// Map<String, Object> map = objectMapper.readValue(msg, Map.class);
Map<String, Object> map = msg;
Integer orderId = (Integer) map.get("orderId");
Integer userId = (Integer) map.get("userId");
String content =(String) map.get("content");
update = jdbcTemplate.update(sqlString, orderId, userId, 123, content, simpleDateFormat.format(new Date(System.currentTimeMillis())));
//由于配置设置了手动应答,所以这里要进行一个手动应答。注意:如果设置了自动应答,这里又进行手动应答,会出现double ack,那么程序会报错。
int i =1/0;
channel.basicAck(message.getMessageProperties().getDeliveryTag(),false);
}catch (Exception e){
/*
如果出现移除的情况下,根据实际情况进行重发
重发一次后,丢失还是日志,根据业务决定
参数1 消息的tag 参数2 false 多条处理,参数3 是否重发
false不会重发,会把消息打入死信队列
true 会死循环的重发,建议如果使用true,不要加try/catch或者死循环,因为不会触发限制的重试次数
*/
channel.basicNack(message.getMessageProperties().getDeliveryTag(),false, false);
}
}try+catch+ack + 死信队列+人工干预
队列增加死信队列,如果再处理失败,通过发邮件等方式预紧. 可对数据进行日志打印或持久化已方便处理
消息消费时可能存在消息幂等性的问题.可通过db唯一索引或分布式锁保证幂等性
总结
基于MQ的分布式事务解决方案优点:
1、通用性强
2、拓展方便
3、耦合度低,方案也比较成熟
基于MQ的分布式事务解决方案缺点:
1、基于消息中间件,只适合异步场景
2、消息会延迟处理,需要业务上能够容忍
建议
1、尽量去避免分布式事务
2、尽量将非核心业务做成异步
运维
持久化机制
RabbitMQ的持久化队列分为:
1:队列持久化
2:消息持久化
3:交换机持久化
不论是持久化的消息还是非持久化的消息都可以写入到磁盘中,只不过非持久的是等内存不足的情况下才会被写入到磁盘中。
队列持久化
队列的持久化是定义队列时的durable参数来实现的,Durable为true时,队列才会持久化。非持久化队列在服务重启时会丢失
// 参数1:名字
// 参数2:是否持久化,
// 参数3:独du占的queue,
// 参数4:不使用时是否自动删除,
// 参数5:其他参数
channel.queueDeclare(queueName,true,false,false,null);消息持久化
消息持久化是通过消息的属性deliveryMode来设置是否持久化,在发送消息时通过basicPublish的参数传入。
// 参数1:交换机的名字
// 参数2:队列或者路由key
// 参数3:是否进行消息持久化
// 参数4:发送消息的内容
channel.basicPublish(exchangeName, routingKey1, MessageProperties.PERSISTENT_TEXT_PLAIN, message.getBytes());交换机持久化
和队列一样,交换机也需要在定义的时候设置持久化的标识,否则在rabbit-server服务重启以后将丢失。
// 参数1:交换机的名字
// 参数2:交换机的类型,topic/direct/fanout/headers
// 参数3:是否持久化
channel.exchangeDeclare(exchangeName,exchangeType,true);